 Prometheus: Prometheus 警報簡介
Prometheus: Prometheus 警報簡介
此文件屬於警報指南的一部分。請在此處查看完整指南:Prometheus 警報的運作方式及其配置方法。
👋 歡迎來到 Stackhero 文件!
Stackhero 提供一個即用型的 Prometheus cloud 解決方案,帶來多項好處,包括:
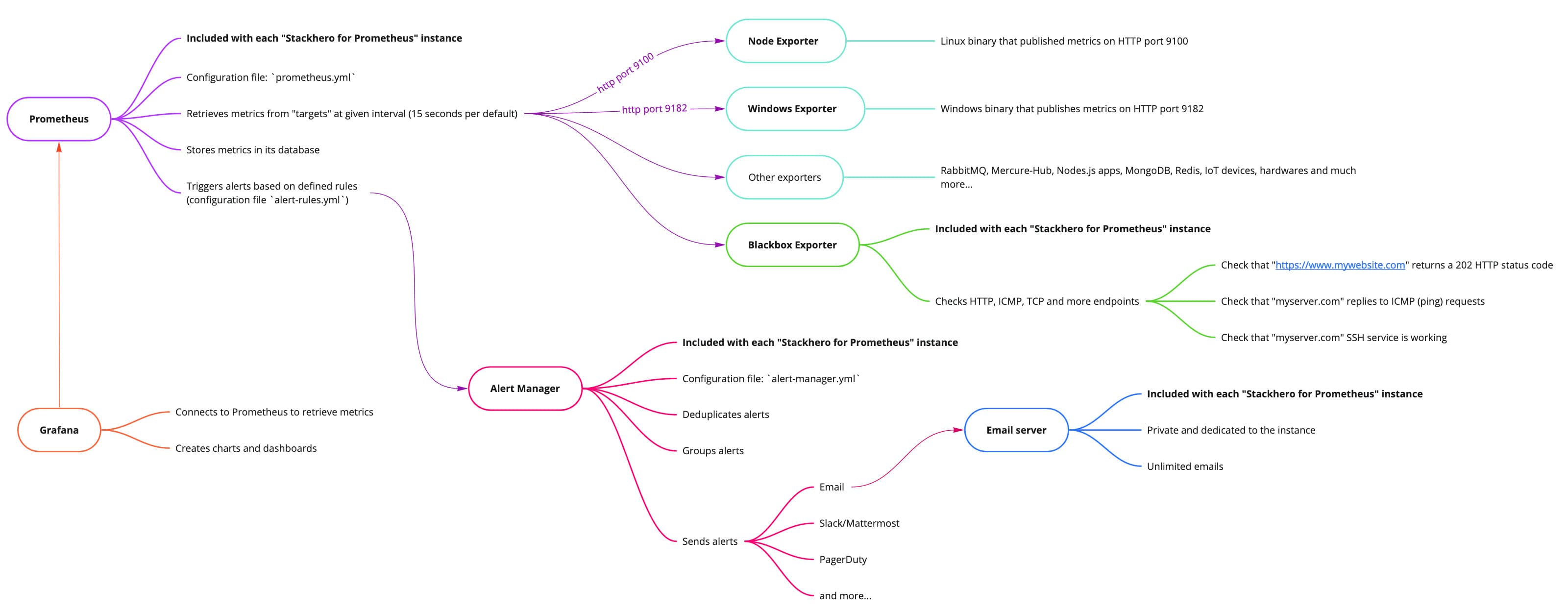
- 包含
Alert Manager,可發送警報至Slack、Mattermost、PagerDuty等。- 專用電郵伺服器發送無限電郵警報。
Blackbox用於探測HTTP、ICMP、TCP等。- 使用線上配置文件編輯器進行簡易配置。
- 只需點擊即可輕鬆完成更新。
- 由專用私有 VM提供的最佳性能和強大安全性。
節省時間並簡化您的生活:只需 5 分鐘即可嘗試 Stackhero 的 Prometheus cloud hosting 解決方案!
Prometheus 可以分析您的指標並根據您定義的規則觸發警報。使用 Stackhero for Prometheus,警報分兩個階段處理。首先,評估 Prometheus 警報規則,然後由 Alert Manager 接手。
所有內容都已預先安裝並配置在 Stackhero for Prometheus 中,因此您只需進行最少的設置,例如添加您的電子郵件地址,即可開始接收警報。
 Stackhero for Prometheus 的大圖
Stackhero for Prometheus 的大圖
Prometheus 警報規則簡介
當 Prometheus 獲取指標時,它會根據 rules-alert.yml 文件中指定的規則進行評估。這些警報規則定義了根據收集的指標觸發警報的閾值和時間窗口。
例如,如果磁碟使用量超過 80%,則可以觸發警報。此外,可以設置規則來預測未來的情況,並在估計磁碟空間將在未來 24 小時內完全填滿時發送警報。
另一個常見的用例是檢測異常行為。例如,如果網絡帶寬使用量突然激增,可以觸發警報以幫助檢測潛在的分佈式拒絕服務 (DDoS) 攻擊或數據外洩嘗試。
Prometheus 警報規則直接包含在 Prometheus 服務器中。
Alert Manager 簡介
Alert Manager 接收由 Prometheus 警報規則觸發的警報。它會去重警報,將其分組,然後通過各種通知渠道(如電子郵件、Slack、Mattermost、PagerDuty 等)轉發。其配置文件為 alert-manager.yml。
例如,如果發生服務器減速,Prometheus 警報規則可能會觸發針對負載增加和 CPU 使用率的單獨警報。Alert Manager 接收這些警報,將其分組,因為它們涉及同一服務器,並根據您的配置向適當的收件人或團隊發送單一合併通知。
如果減速持續,Prometheus 將繼續發送警報,但 Alert Manager 會在指定時間內抑制重複消息,以防止您的團隊被冗餘警報淹沒。
如果需要,您還可以靜音或完全抑制警報。一旦解決了根本問題,將發送恢復消息以通知您的團隊。
此示例說明了一個常見場景,但您可以完全自定義設置以滿足您的特定需求。
警告
Alert Manager並未預設包含在 Prometheus 中。 為了節省您的時間並簡化過程,我們已在 Stackhero for Prometheus 中集成並配置了Alert Manager,因此您只需幾分鐘即可發送警報,幾乎不需要任何努力。