 Prometheus: Prometheus 警报简介
Prometheus: Prometheus 警报简介
本文件是警报指南的一部分。您可以在这里查看完整指南:Prometheus 警报的工作原理及其配置方法。
👋 欢迎来到 Stackhero 文档!
Stackhero 提供即用型 Prometheus 云 解决方案,具有多种优势,包括:
- 包含
Alert Manager,可发送警报到Slack、Mattermost、PagerDuty等。- 专用邮件服务器发送无限制邮件警报。
Blackbox用于探测HTTP、ICMP、TCP等。- 使用在线配置文件编辑器进行轻松配置。
- 只需点击即可轻松更新。
- 由专用私有 VM提供的最佳性能和强大安全性。
节省时间,简化生活:只需 5 分钟即可试用 Stackhero 的 Prometheus 云托管 解决方案!
Prometheus 可以分析您的指标并根据您定义的规则触发警报。使用 Stackhero for Prometheus,警报分两个阶段处理。首先,评估 Prometheus 警报规则,然后由 Alert Manager 接管。
一切都已通过 Stackhero for Prometheus 预安装和配置,因此您只需进行最少的设置,例如添加您的电子邮件地址,即可开始接收警报。
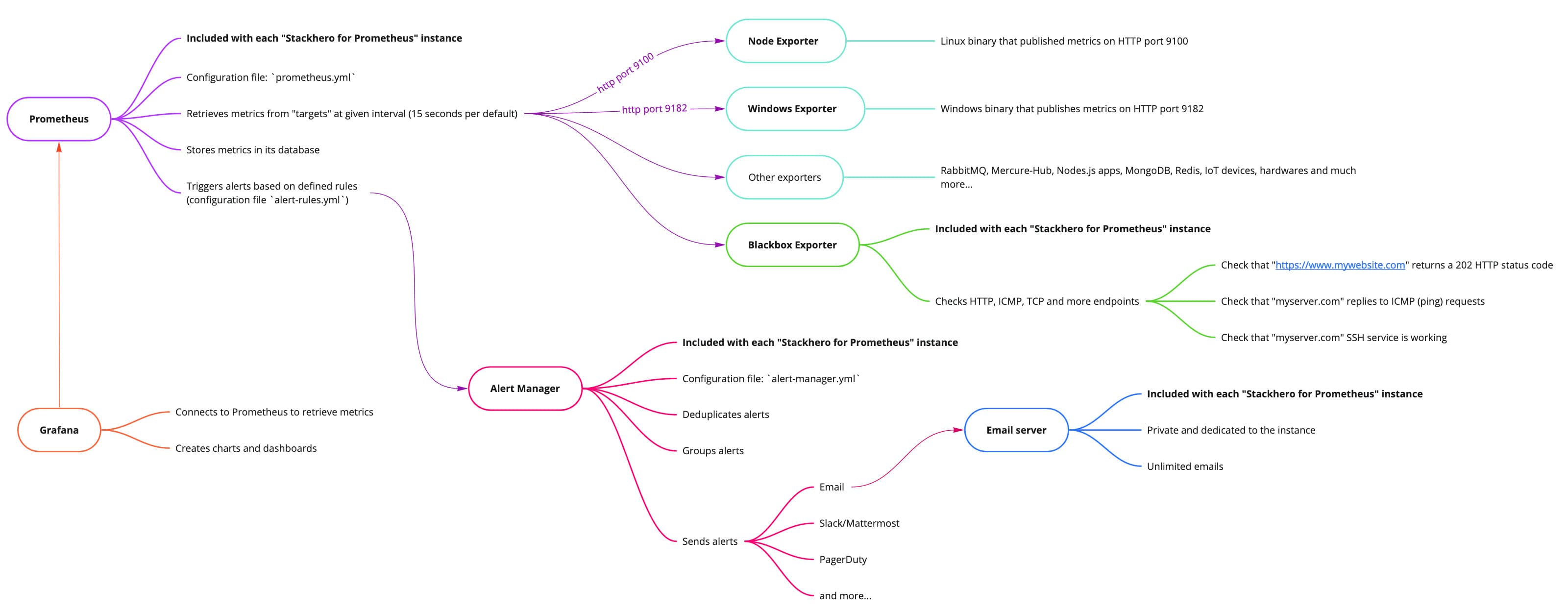 Stackhero for Prometheus 的全景图
Stackhero for Prometheus 的全景图
Prometheus 警报规则简介
当 Prometheus 检索指标时,它会根据 rules-alert.yml 文件中指定的规则进行评估。这些警报规则定义了触发警报的阈值和时间窗口。
例如,如果磁盘使用率超过 80%,可以触发警报。此外,可以设置规则来预测未来的情况,并在估计磁盘空间将在接下来的 24 小时内完全填满时发送警报。
另一个常见的用例是检测异常行为。例如,如果网络带宽使用突然激增,可以触发警报以帮助检测潜在的分布式拒绝服务 (DDoS) 攻击或数据泄露尝试。
Prometheus 警报规则直接包含在 Prometheus 服务器中。
Alert Manager 简介
Alert Manager 接收由 Prometheus 警报规则触发的警报。它去重警报,将其分组,然后通过各种通知渠道(如电子邮件、Slack、Mattermost、PagerDuty 等)转发。其配置文件为 alert-manager.yml。
例如,如果服务器减速发生,Prometheus 警报规则可能会触发针对负载增加和 CPU 使用率的单独警报。Alert Manager 接收这些警报,将其分组,因为它们与同一服务器相关,并根据您的配置向适当的收件人或团队发送单个合并通知。
如果减速持续,Prometheus 将继续发送警报,但 Alert Manager 将在指定时间内抑制重复消息,以防止您的团队被冗余警报淹没。
如果需要,您还可以静音或完全抑制警报。一旦解决了根本问题,将发送恢复消息以通知您的团队。
此示例说明了一个常见场景,但您可以完全自定义设置以满足您的特定需求。
警告
Alert Manager默认不包含在 Prometheus 中。 为了节省您的时间并简化流程,我们已在 Stackhero for Prometheus 中集成并配置了Alert Manager,因此您可以在几分钟内发送警报,几乎不费力。